Wan AI Video Generator — Complete Guide to Alibaba's Open-Source Video Model
Everything you need to know about the Wan AI video generator: architecture, benchmarks, local setup, cloud API, pricing, and how it compares to Sora, Kling, and Runway.
The Wan AI video generator is an open-source text-to-video and image-to-video model developed by Alibaba's Tongyi Lab. Released under the Apache 2.0 license, it consistently outperforms closed-source competitors on the VBench benchmark — scoring 86.22% overall versus Sora's 84.28% — while remaining completely free for commercial use. Whether you want to run Wan locally on a single GPU or access the full 14-billion-parameter model through a cloud API, this guide covers everything from architecture to pricing so you can start generating cinematic AI video today.
What Is the Wan AI Video Generator?
The Wan AI video generator is a family of open-source video generation models created by Alibaba's Tongyi Laboratory. Unlike closed-source alternatives such as OpenAI's Sora or Google's Veo, the entire Wan model suite — including weights, training code, and inference scripts — is publicly available under the Apache 2.0 license. That means anyone can download, modify, fine-tune, and deploy Wan for commercial projects without royalty fees.
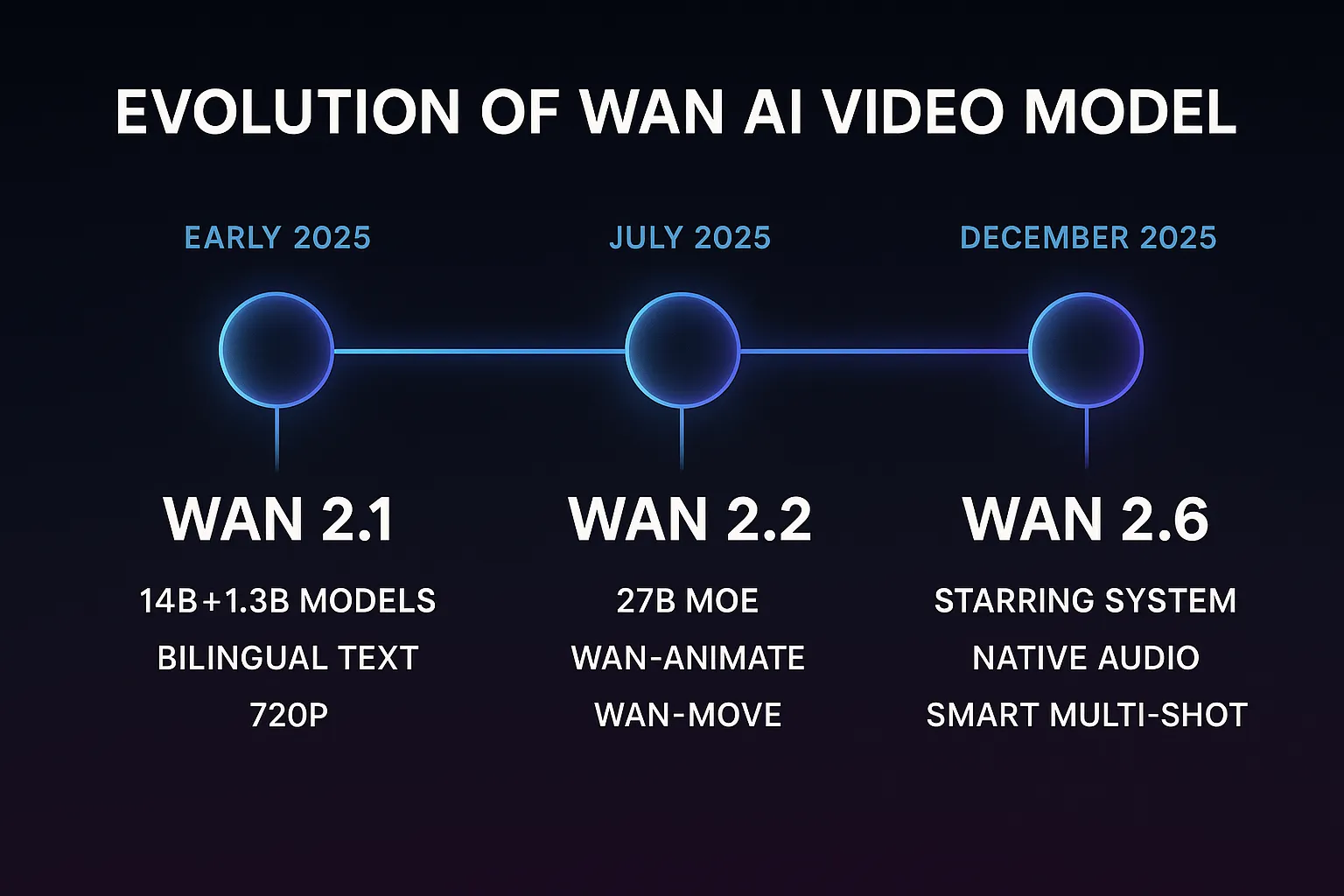
The name "Wan" (万) means "ten thousand" in Chinese, representing the model's ambition to handle the vast diversity of visual content. Since its initial release in early 2025, Wan has evolved through three major versions, each adding significant capabilities: from basic text-to-video in version 2.1, through efficiency-focused mixture-of-experts in 2.2, to narrative-grade multi-shot storytelling in 2.6.
What makes the Wan video generator particularly attractive for creators and developers is its dual-model approach. A lightweight 1.3-billion-parameter model runs on consumer GPUs for rapid prototyping, while the full 14-billion-parameter model delivers cinematic quality rivaling the best commercial services. This flexibility makes Wan accessible to solo creators experimenting on a laptop and production studios running cloud infrastructure alike.
Version Evolution: From Wan 2.1 to Wan 2.6
Wan 2.1: The Foundation (Early 2025)
Wan 2.1 established the architectural foundation that all later versions build upon. It shipped with two model sizes — the full 14B parameter model for maximum quality and a distilled 1.3B model for faster, consumer-hardware inference. Key capabilities at launch included:
- Text-to-Video (T2V): Generate 480p or 720p video clips up to 5 seconds from natural language prompts
- Image-to-Video (I2V): Animate a static image into fluid motion while preserving the source composition
- Bilingual prompting: Native support for both English and Chinese text input via the umT5 encoder
- High aesthetic scores: First open-source model to surpass all commercial competitors on the VBench composite benchmark
Even at version 2.1, the Wan AI video generator demonstrated remarkably coherent motion, accurate text rendering within video frames, and strong prompt adherence — areas where many earlier open-source models struggled.
Wan 2.2: The Efficiency Leap (July 2025)
Version 2.2 introduced the 27-billion-parameter Mixture-of-Experts (MoE) architecture, a major leap in inference efficiency. Rather than activating all parameters for every frame, the MoE design routes each computation through specialized expert networks, cutting generation time significantly while improving output quality.
New modules introduced in Wan 2.2:
- Wan-Animate: Character animation from a single reference image, maintaining identity consistency across frames
- Wan-Move: Motion transfer that applies the movement from one video to a different subject
- Enhanced I2V pipeline: Smoother transitions, better temporal coherence, and support for longer clips
- Optimized inference: The 27B MoE model activates only a fraction of its parameters per token, achieving quality above the dense 14B model at similar speed
The 2.2 release of the Wan AI video generator cemented its position as the most capable open-source video model available, with community benchmarks confirming quality improvements across motion realism, color accuracy, and prompt fidelity.
Wan 2.6: The Narrative Era (December 2025)
Wan 2.6 shifted focus from single-clip generation to coherent video storytelling. Three headline features define this release:
- Starring System (R2V — Reference-to-Video): Provide a character reference image and Wan maintains that character's appearance across multiple independently generated clips. This enables consistent protagonist identity throughout an entire video narrative.
- Native Audio (V2A — Video-to-Audio): Built-in audio generation synchronized to visual content. The model produces ambient sound, dialogue-matched lip timing, and sound effects directly from video frames — no external audio pipeline required.
- Smart Multi-Shot: Automatically decompose a long narrative prompt into individual shots with appropriate transitions, camera angles, and pacing. This transforms the Wan video generator from a clip tool into a short-film engine.
Wan 2.6 also improved base generation quality, with the 14B model now supporting up to 1080p resolution and 10-second clips in a single pass, with multi-shot concatenation enabling longer narratives.
Technical Architecture
The Wan AI video generator is built on three core innovations that differentiate it from competing models. Understanding these components helps explain why Wan achieves superior benchmark scores while maintaining practical inference speeds.
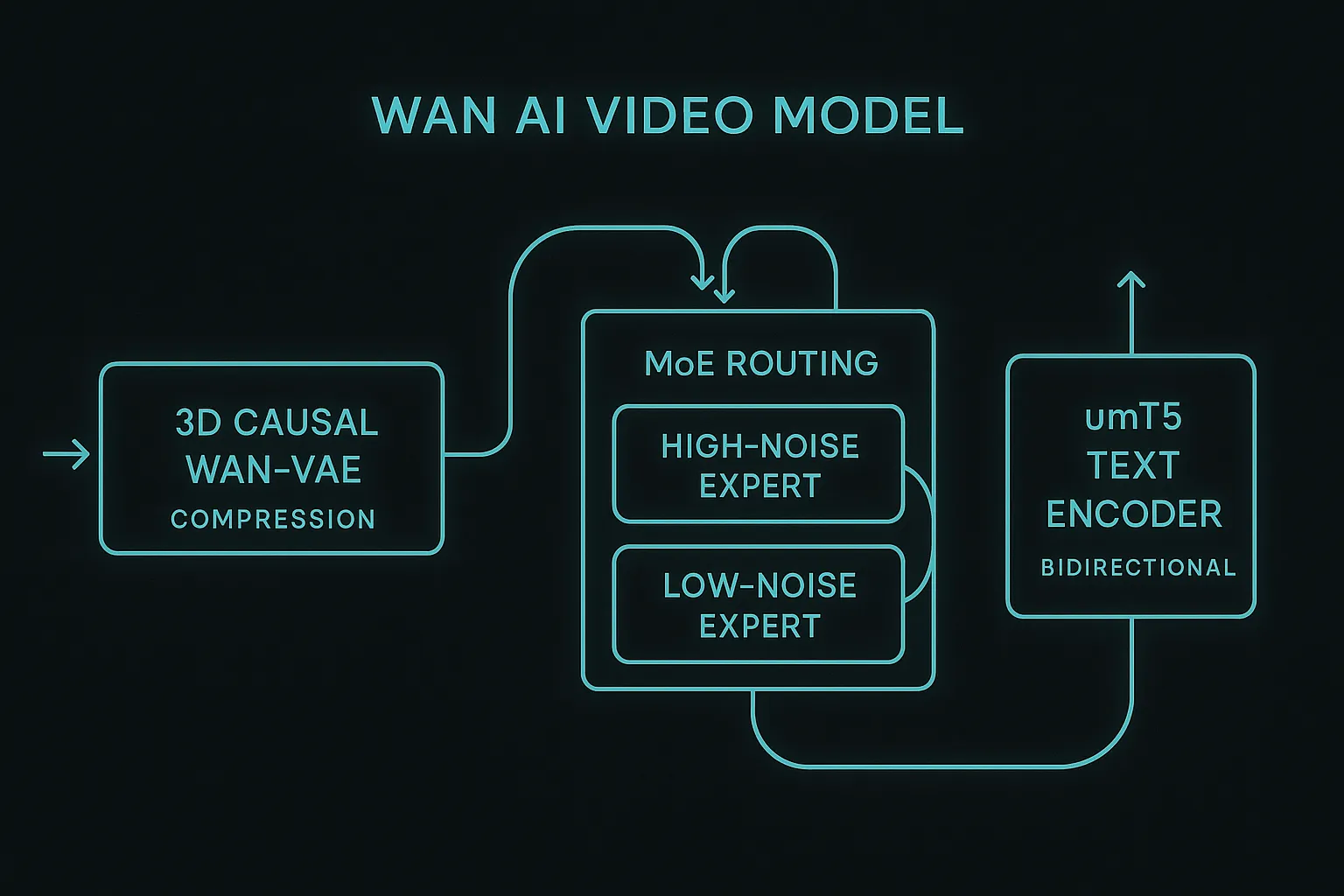
3D Causal Wan-VAE
At the heart of Wan's pipeline is a custom 3D Causal Variational Autoencoder (Wan-VAE) that compresses raw video frames into a compact latent space. Unlike standard image VAEs that process frames independently, Wan-VAE operates across three dimensions — height, width, and time — capturing temporal relationships directly in the latent representation.
The key innovation is the Feature Cache Mechanism: rather than recomputing spatial features for every temporal step, the encoder caches intermediate feature maps and reuses them across adjacent frames. This reduces redundant computation by roughly 60% during encoding, making Wan-VAE approximately 2.5x faster than the VAE used in HunyuanVideo while producing higher-fidelity reconstructions.
Mixture-of-Experts (MoE) Routing
Starting with Wan 2.2, the diffusion backbone uses a Mixture-of-Experts architecture that routes each denoising step through specialized sub-networks:
- High-Noise Expert: Activated during early denoising steps where the model establishes global layout, composition, and large-scale motion trajectories
- Low-Noise Expert: Engaged during later steps to refine fine textures, lighting details, facial expressions, and sub-pixel motion
This routing means the 27B model only activates approximately 8-10B parameters per step, delivering output quality that exceeds the dense 14B model at comparable inference cost. The MoE approach also enables more graceful quality scaling — users can trade speed for quality by adjusting the number of denoising steps without the harsh quality cliffs common in dense models.
umT5 Text Encoder
Wan uses a unified multilingual T5 (umT5) text encoder rather than the CLIP-based encoders common in image generators. Key advantages:
- Bidirectional attention: Unlike CLIP's unidirectional processing, umT5 understands context from both directions, producing richer semantic representations of complex prompts
- Native bilingual support: Trained jointly on English and Chinese text, enabling natural prompting in either language without translation artifacts
- Long-context handling: Supports prompts up to 512 tokens, allowing detailed scene descriptions, multi-character interactions, and specific camera direction within a single prompt
Benchmark Performance
The Wan AI video generator holds the highest composite score on VBench, the most widely adopted benchmark for AI video generation. Here's how the major models compare:
| Model | VBench Score | Resolution | Max Duration | Text Rendering | Open Source |
|---|---|---|---|---|---|
| Wan 2.2 (14B) | 86.22% | 720p–1080p | 10s | Strong | Yes (Apache 2.0) |
| Sora (OpenAI) | 84.28% | 1080p | 20s | Moderate | No |
| Runway Gen-3 | 82.32% | 1080p | 10s | Weak | No |
| Kling 1.5 (Kuaishou) | 81.85% | 1080p | 10s | Moderate | No |
| Pika 1.5 | 80.61% | 720p | 4s | Weak | No |

Beyond the composite score, the Wan video generator excels in several specific categories:
- Motion quality: Wan's temporal coherence outperforms all tested models, with fewer artifacts during fast camera movements and complex subject motion
- Text rendering in video: Wan is the first open-source model to reliably render readable text on signs, screens, and objects within generated video — a capability previously limited to Sora
- Prompt adherence: The umT5 encoder provides measurably better alignment between complex multi-element prompts and generated output
- Aesthetic quality: Professional colorimetry and natural lighting that rivals footage from physical cameras
The most significant advantage, however, may be availability. While Sora requires a ChatGPT Pro subscription ($200/month) with generation limits, and Runway charges per-second generation fees, the full Wan model can be self-hosted at zero marginal cost per generation after initial hardware investment.
Running Wan: Local vs Cloud
Local Setup (1.3B Speed Edition)
Running the Wan AI video generator locally is ideal for rapid prototyping, iterating on prompts, and generating content without per-clip costs. The 1.3B model is optimized for consumer hardware:
Minimum requirements:
- GPU: NVIDIA RTX 4090 (24GB VRAM) or equivalent
- RAM: 32GB system memory
- Storage: ~15GB for model weights
- OS: Linux (recommended) or Windows with WSL2
What to expect:
- Resolution: 480p (832 x 480)
- Generation time: ~4 minutes for a 5-second clip
- Quality: Good for storyboarding, social media drafts, and concept validation
- Cost: Free after hardware investment
Quick start:
git clone https://github.com/Wan-Video/Wan2.1
cd Wan2.1
pip install -r requirements.txt
# Text-to-Video generation
python generate.py \
--task t2v-1.3B \
--size 832*480 \
--prompt "A cat walking across a sunlit windowsill, dust particles floating in golden light"
The 1.3B model is the best entry point for creators who want to experiment with the Wan video generator without cloud costs. Quality is genuinely usable for social media content, especially after basic post-processing.
Cloud API (14B Pro Edition)
For production-quality output, the full 14B model delivers cinematic results through cloud API providers:
Recommended providers:
- DashScope (Alibaba Cloud): Official API with the latest model versions, $0.10–0.15 per 5-second clip at 720p
- SiliconFlow: Third-party hosting with competitive pricing, $0.12–0.29 per clip depending on resolution and duration
- Replicate: Pay-per-second pricing, easy integration with existing workflows
What to expect:
- Resolution: 720p to 1080p
- Generation time: 30–90 seconds depending on provider and queue
- Quality: Cinematic, suitable for commercial content, ads, and professional video production
- Cost: $0.10–0.29 per clip

For most creators, a hybrid approach works best: prototype with the local 1.3B model, then generate final output through the cloud 14B API. This workflow minimizes cloud costs while maintaining the iteration speed needed for creative work.
Pricing and Licensing
The Wan AI video generator is released under the Apache 2.0 license, which is one of the most permissive open-source licenses available. In practical terms, this means:
- Free commercial use: You can sell content generated by Wan without royalties or attribution requirements
- Free modification: Fine-tune the model on your own data, modify the architecture, and distribute your changes
- No usage tracking: Self-hosted Wan sends no telemetry or usage data to Alibaba
- Patent grant: The Apache 2.0 license includes an explicit patent grant, protecting users from patent claims on the covered technology
Cost Breakdown
| Deployment Method | Upfront Cost | Per-Clip Cost | Best For |
|---|---|---|---|
| Local 1.3B (RTX 4090) | $1,600–2,000 (GPU) | ~$0.01 electricity | Prototyping, high-volume social content |
| Local 14B (A100 80GB) | $10,000–15,000 (GPU) | ~$0.03 electricity | Studios with consistent workloads |
| Cloud API (DashScope) | $0 | $0.10–0.15/clip | Production quality on demand |
| Cloud API (SiliconFlow) | $0 | $0.12–0.29/clip | Flexible usage, no commitment |
| Cloud GPU Rental (RunPod) | $0 | $1.50–3.00/hour | Full control, intermittent use |

Compared to closed-source alternatives — Sora requires a $200/month ChatGPT Pro subscription, Runway charges $0.25–0.50 per second of video, and Kling starts at $0.30 per clip — the Wan AI video generator offers the most cost-effective path to high-quality AI video at any volume.
2026 Roadmap
Alibaba's Tongyi Lab has outlined several developments expected through 2026:
- Wan 3.0 (60B parameters): A significantly larger model targeting 4K resolution and 30-second continuous generation in a single pass, expected mid-2026
- 1440p / 4K support: Native ultra-high-resolution output for broadcast and cinema workflows
- Real-time generation: Optimizations targeting interactive frame rates for live applications
- Extended multi-shot: Automated generation of 2–5 minute narratives with consistent characters, settings, and pacing
- Community fine-tuning ecosystem: Official tools and datasets for domain-specific model adaptation (product ads, animation styles, architectural visualization)
The open-source nature of Wan means the community is also actively contributing improvements. Third-party optimization projects have already achieved 30-40% faster inference through quantization and custom CUDA kernels, and LoRA fine-tuning adapters are proliferating for specialized styles and subjects.
Try Wan Models on ZenCreator — No Setup Required
Don't want to deal with GPU requirements and local installation? ZenCreator runs Wan models in the cloud so you can start generating immediately — no hardware, no API keys, no configuration.
Image-to-Video with Wan
ZenCreator offers four Wan video models for image-to-video generation:
- WAN 2.2 + LoRAs — Wan with LoRA support for consistent style and characters. Supports start frame and unrestricted content.
- WAN 2.2 — The most flexible model for creative motion. Supports start frame, end frame, and unrestricted content.
- Wan 2.5 + Audio — Audio-driven motion with lip-sync and rhythm matching. Supports start frame and audio input.
- Wan 2.6 + Audio — Latest version with improved audio-driven generation, lip-sync, and rhythm control. Supports start frame and audio input.
All models support NSFW content generation — no filters, no restrictions on creative output.
Text-to-Image with Wan
ZenCreator also includes a Wan text-to-image model optimized for creative styles, with support for unrestricted content and resolutions up to 1K. Use it to generate starting frames for your video pipeline — create an image from a prompt, then animate it with any of the Wan video models above.
Whether you're prototyping ideas, creating content for social media, or building a full production pipeline, ZenCreator gives you access to the latest Wan models with a simple browser interface and a free tier to get started.
Frequently Asked Questions
What is the Wan AI video generator?
The Wan AI video generator is an open-source video generation model developed by Alibaba's Tongyi Lab. It converts text prompts or static images into high-quality video clips using a diffusion-based architecture with a 3D Causal VAE and Mixture-of-Experts design. It is available under the Apache 2.0 license, making it free for both personal and commercial use.
Is Wan AI video generator free to use?
Yes, the Wan AI video generator is completely free to use. The model weights, training code, and inference scripts are all released under the Apache 2.0 license with no usage fees or royalties. The only costs are your own compute resources — either a local GPU or cloud API fees, which start at approximately $0.10 per clip.
How to run Wan AI video generator locally?
To run the Wan AI video generator locally, you need an NVIDIA GPU with at least 24GB VRAM (such as an RTX 4090) for the 1.3B model. Clone the official repository from GitHub, install the Python dependencies, and run the generation script with your prompt. The 1.3B model generates a 5-second 480p clip in approximately 4 minutes on consumer hardware.
What's the difference between Wan 2.1, 2.2, and 2.6?
Wan 2.1 introduced the core text-to-video and image-to-video capabilities with 14B and 1.3B models. Wan 2.2 added a 27B Mixture-of-Experts architecture for better efficiency, plus character animation and motion transfer modules. Wan 2.6 brought narrative storytelling features including consistent character identity across shots, native audio generation, and automated multi-shot decomposition.
Is Wan AI open source?
Yes, the Wan AI video generator is fully open source under the Apache 2.0 license. This includes all model weights (1.3B, 14B, and 27B MoE variants), training code, inference scripts, and documentation. You can freely modify, fine-tune, and deploy the model for any purpose, including commercial applications, without attribution requirements.
How does Wan compare to Sora?
The Wan AI video generator scores higher than Sora on the VBench benchmark (86.22% vs 84.28%), with particular advantages in motion quality and text rendering. Sora offers longer maximum clip duration (20 seconds vs 10 seconds) and slightly higher baseline resolution. The biggest practical difference is access: Wan is free and open source, while Sora requires a $200/month ChatGPT Pro subscription with generation limits.
Can Wan AI generate video from images?
Yes, the Wan AI image-to-video generator is one of its core capabilities. You provide a static image as input, and the model animates it into a fluid video clip while preserving the composition, colors, and subject identity from the source image. Starting with Wan 2.2, the Wan-Animate module also supports character-specific animation from a single reference photo.